编译原理实验2——正则表达式->NFA->DFA->MFA
1、词法分析理论基础:有穷自动机(FA)
1.1 起源与定义
- 有穷自动机(Finite Automata,FA)由两位神经物理学家MeCuloch和Pitts于1948年首先提出,是对一类处理系统建立的数学模型;
- 这类系统具有一系列离散的输入输出信息和有穷数目的内部状态(状态:概括了对过去输入信息处理的状况);
- 系统只需要根据当前所处的状态和当前面临的输入信息就可以决定系统的后继行为。每当系统处理了当前的输入后,系统的内部状态也将发生改变。
1.2 FA分类
- 确定的FA(Deterministic finite automata, DFA)
- 非确定的FA(Nondeterministic finit automata, NFA)
1.3 确定的有穷自动机(DFA)
DFA被定义为一个五元组:M = ( S , Σ , δ , S0 , F )
- S:有穷状态集;
- Σ:输入字母表,即输入符号集合。假设ε不是Σ中的元素;
- δ:将S×Σ映射到S的转换函数。∀ s ∈ S , a ∈ Σ , δ ( s , a ) 表示从状态s出发,沿着标记为a的边所能到达的状态(即状态S对应于输入符号的后继状态);
- S0:开始状态(或初始状态),S0∈S;
- F:接收状态(或终止状态)集合,F⊆S。
1.4 非确定的有穷自动机(NFA)
NFA被定义为一个五元组:M = ( S , Σ , δ , S0 , F )
- S:有穷状态集;
- Σ:输入字母表,即输入符号集合。假设ε不是Σ中的元素;
- δ:将S×Σ映射到S的转换函数。∀ s ∈ S , a ∈ Σ , δ ( s , a ) 表示从状态s出发,沿着标记为a的边所能到达的状态(即状态S对应于输入符号的后继状态);
- S0:开始状态(或初始状态)集合,S0⊆S;
- F:接收状态(或终止状态)集合,F⊆S。
1.5 DFA和NFA的等价性
- 对任何非确定的有穷自动机N ,存在定义同一语言的确定的有穷自动机D;
- 对任何确定的有穷自动机D ,存在定义同一语言的非确定的有穷自动机N;
2、算法1:NFA确定化为DFA
DFA确定化的核心算法: 子集法
通俗的说:首先明确,
- NFA中的多个状态,共同组成了DFA中的多个状态。
- 我们先将NFA的初态集的闭包入队,然后BFS
- 每次从queue中取出一个状态集,用字母表的每个字母对其进行一次转换后取闭包(ε-closure(move(State))),如果产生新状态则入队,继续BFS。
其中,较为关键是基于一次转化函数的move、以及ε-closure闭包函数。代码中专门有注释说明。
2.1 首先定义NFA和DFA的JavaBean类
1 | import java.util.List; |
1 | import java.util.List; |
2.2 子集法核心逻辑实现
1 | import java.util.*; |
2.3 定义ReadNFAUtil工具类获取NFA五元组的信息
1. 准备一个NFA作为测试案例
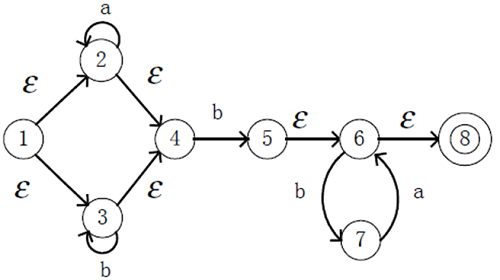
2. 将对应的五元组写入txt文件
注意:状态从0开始定义
1 | S=01234567 |
这里将其命名为NTD.txt
3. 定义ReadNFAUtil工具类,读入五元组信息
1 | public class ReadNFAUtil { |
4. 定义DisplayUtils工具类,用于打印nfa、dfa对象
1 | public class DisplayUtils { |
2.4 定义测试类NTDTest
- 定义一个NTDTest类进行测试
1 | public class NTDTest { |
- 测试结果如下:
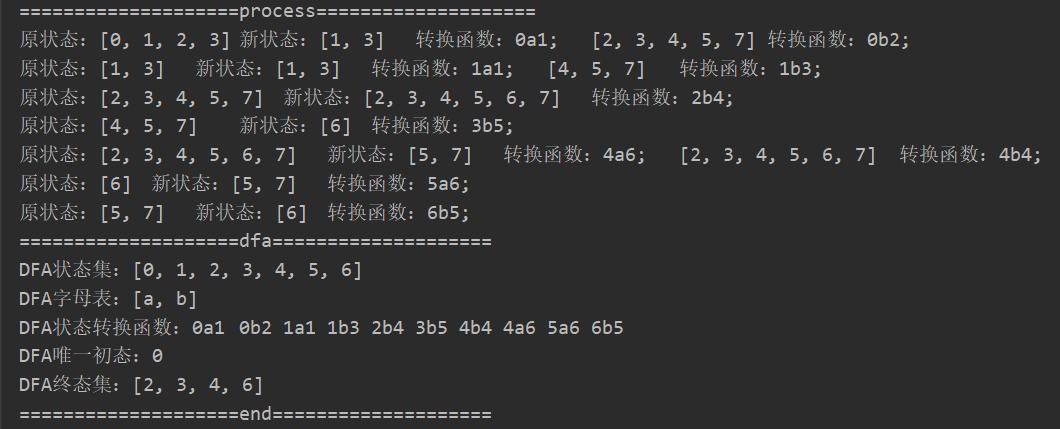
- process过程对照结果
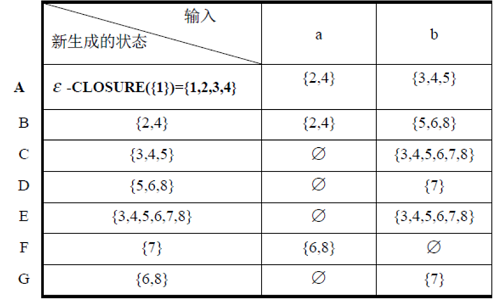
注:这里的分组重新标号为0123...,对应图中的ABCD..
- 生成的dfa对照结果
- 结果正确,可测试多组案例,确认无误再往下进行
3、算法2:DFA最小化为MFA
注:DFA的最小化也称为:确定的有穷状态机的化简。
3.1 算法说明
DFA的最小化 = 消除无用状态 + 合并等价状态
- 消除无用状态这里是指删掉那些达到不了的状态。这不是我们的重点,DFS+HashSet不难实现。
- 其实关键在于合并等价状态。那么,怎样的两个状态是等价的呢?
状态的等价需要满足两个条件:
- 一致性条件:它们都是可接受状态或不可接受状态(即都是终态或非终态)
- 蔓延性条件:我们用所有的输入符号进行转化,它们都可以转化到等价的状态里
DFA最小化核心算法:分割法
算法步骤如下::
- 先根据终态/非终态分为两组
- 然后对同一组中的状态,用所有输入符号去试着转化,如果转化不到一组,则再分
- 不断进行上述操作,直到每一组各自的状态集通过任何一个字母都不会转移到其他组
3.2 定义Group的JavaBeen类,用于分组
1 | public class Group { |
3.3 分割法核心逻辑实现
1 | /** |
3.4 定义ReadDFAUtil工具类获取DFA五元组的信息
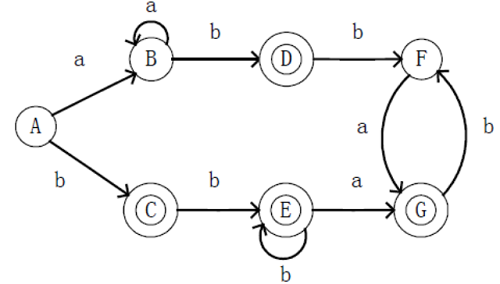
1. 准备一个DFA作为测试案例
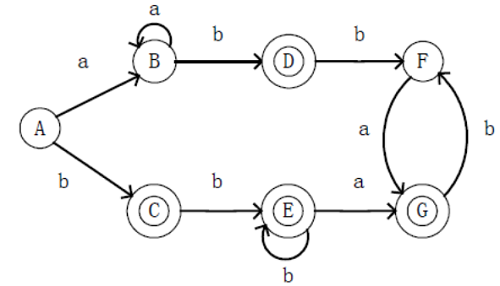
2. 将对应的五元组写入txt文件
注意:状态从0开始定义
1 | S=0123456 |
这里将其命名为MinDFA.txt
3. 定义ReadDFAUtil工具类,读入五元组信息
注:和ReadNFAUtil基本相同,只有读入S0有区别,此处代码略
4. DisplayUtils工具类已在算法1中定义
3.5 定义测试类MinDFATest
- 定义一个NTDTest类进行测试
1 | public class MinDFATest { |
- 测试结果如下:
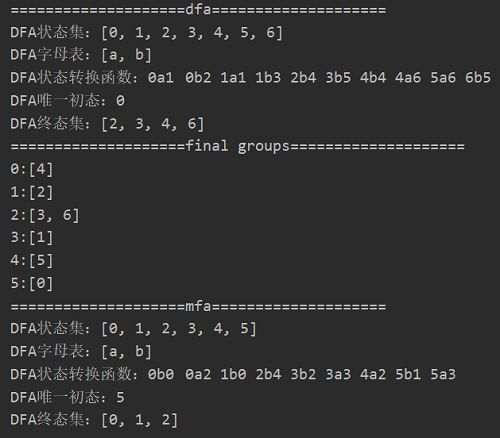
注:这里的分组重新标号为0123...,而不是图中的ABCD..
- 生成的mfa对照结果
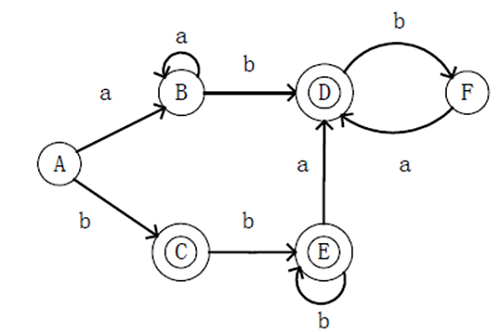
- 结果正确,可测试多组案例,确认无误再往下进行
3、算法3:正则表达式转换为NFA
3.1 首先定义Node和Edge的JavaBeen类
1 | public class Node { |
1 | public class Edge { |
3.2 定义Graph类用于构造NFA
1 | public class Graph { |
3.3 核心逻辑实现
1 | public class Regex { |
3.4 定义测试类Main
1 | public class Main { |
输出结果:
1 | 待转换的正则表达式:(ab|c)*abb |
可在草稿纸上做出对应MFA进行检验,尝试多组案例观察结果是否正确
以上则是编译原理实验:正则表达式->NFA->DFA->MFA 实现的全部内容啦!